當 AI 開始執行,治理必須超越對話。
最初我們使用大型語言模型(LLM),是為了解釋程式碼、生成文件,或協助思考。但今天的 AI Agent 已經跨越了一個關鍵門檻。它們現在正在修改程式碼、重構模組、修改設定,甚至觸發部署流程。
它們不再只是「建議者(Advisors)」;它們是 行動者(Actors)。
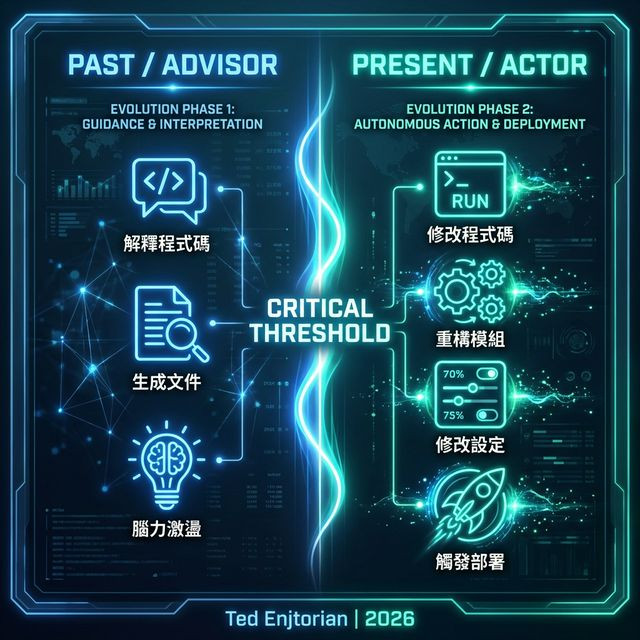
真正讓團隊焦慮的,往往不是 AI 做錯事,而在於當事情發生時,無法回答簡單的問題:
聊天記錄不等於治理。
Prompt 設計也不等於責任邊界。
POG 不是另一種 prompt engineering。它解決的是目前系統中一個根本的缺口:
當 AI 做出一個影響系統的動作時,人類是否還能理解、審查並重播這個決策?
如果不能,那這不是自動化;這是 風險放大器。
在多 Agent 系統中,這個問題被放大了。當你有 Planner Agent、Executor Agent 和 Reviewer Agent 時,「prompt」變成了隱藏在視線之外的內部訊息流。
治理往往停留在單一對話層級,這造成了 結構性錯位:行動發生了,但責任邊界消失了。
我們很快就會發現,治理 prompt 只能管理「想法」,而無法管理「行動」。
當 AI 開始做實際工作時,prompt 告訴它「做什麼」,但完全沒有處理:
傳統上,這些責任是由「任務系統」承擔的。然而,像 Jira 或 Linear 這樣的現有工具在這裡並不適用。
現有的任務系統基於特定的假設:人類閱讀 UI,人類更新狀態,人類記住上下文。
AI 不會。
對 AI 而言,UI 是不可見的,狀態必須是機器可解析的,歷史必須是結構化的。

POG 引導我們得出一個單一且關鍵的結論:
任務本身,必須成為治理單位。
不是聊天視窗。不是 Log。不是工具狀態。
為了治理 AI 行動者,我們需要 可執行、可審查的任務描述,作為人類意圖與機器執行之間的約束合約。POG 的出現不是為了限制 AI,而是為了讓 AI 的行動重新進入人類可理解的系統邊界。
👉 下一篇:[從治理到執行:POG Task 設計與 MVP]
 enjtorian
enjtorian
